


Tiếp tục phần 2 của loạt bài tìm hiểu toàn cảnh về Ensemble Learning, trong phần này ta sẽ đi qua một số thuât toán thuộc nhóm Bagging và Boosting.
- Các thuật toán thuộc nhóm
Baggingbao gồm:- Bagging meta-estimator
- Random forest
- Các thuật toán thuộc họ
Boostingbao gồm:- AdaBoost
- Gradient Boosting (GBM)
- XGBoost (XGBM)
- Light GBM
- CatBoost
Để minh họa cho các thuật toán kể trên, mình sẽ sử dụng bộ dữ liệu Loan Prediction Problem.
1. Bagging techniques
1.1 Bagging meta-estimator
Bagging meta-estimator là thuật toán sử dụng cho cả 2 loại bài toán classification (BaggingClassifier) và regression (BaggingRegressor).
Các bước thực hiện của thuật toán như sau:
- Bước 1: Tạo ngẫu nhiên các N
bagstừ tậptrain set. - Bước 2: Tạo N objects của lớp
BaggingClassifiervà train trên mỗi bag, độc lập với nhau. - Bước 3: Sử dụng các objects đã trained để dự đoán trên tập
test set.
Code cho bài toán classification:
#importing important packages
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import BaggingClassifier
from sklearn import tree
from sklearn.preprocessing import LabelEncoder
#reading the dataset
df = pd.read_csv("train_ctrUa4K.csv")
# drop nan values
df.dropna(inplace=True)
# instantiate labelencoder object
le = LabelEncoder()
# Categorical boolean mask
categorical_feature_mask = df.dtypes==object
# Get list of categorical column names
categorical_cols = df.columns[categorical_feature_mask].tolist()
# apply le on categorical feature columns
df[categorical_cols] = df[categorical_cols].apply(lambda col: le.fit_transform(col))
#split dataset into train and test
train, test = train_test_split(df, test_size=0.3, random_state=0)
x_train = train.drop('Loan_Status',axis=1)
y_train = train['Loan_Status']
x_test = test.drop('Loan_Status',axis=1)
y_test = test['Loan_Status']
model = BaggingClassifier(tree.DecisionTreeClassifier(random_state=1))
model.fit(x_train, y_train)
accuracy = model.score(x_test,y_test)
print("Accuracy: {:.2f}%".format(accuracy*100))Kết quả:
Accuracy: 77.83%Đối với bài toán regression, thay BaggingClassifier bằng BaggingRegressor.
Một số tham số:
- base_estimator: Định nghĩa thuật toán mà
base modelsử dụng. Mặc định làdecision tree. - n_estimators: Định nghĩa số lượng
base models. Mặc định là 10. - max_samples: Định nghĩa số lượng mẫu data tối đa trong mỗi bag. Mặc định là 1.
- max_features: Định nghĩa số lượng features tối đa sử dụng trong mỗi bag. Mặc định là 1.
- n_jobs: Số lượng jobs chạy song song cho cả quá trình train và predict. Mặc định là 1. Nếu giá trị bằng -1 thì số jobs bằng số cores của hệ thống.
- random_state: Nếu tham số này được gán giá trị giống nhau mỗi lần gọi
BaggingClassifierthì các dữ tập dữ liệu con sinh ra (một cách ngẫu nhiên) từ tập dữ liệu ban đầu sẽ giống nhau. Tham số này hữu ích khi cần so sánh các models với nhau.
1.2 Random Forest
Các thức hoạt động của Random Forest gần giống Bagging meta-estimator, chỉ khác một điều duy nhất là tại mỗi node của tree trong Decision Tree, nó tạo ra một tập ngẫu nhiên các features và sử dụng tập này đê chọn hướng đi tiếp theo. Trong khi đó, Bagging meta-estimator sử dụng tất cả features để chọn đường.
Code ví dụ:
#importing important packages
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import tree
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
#reading the dataset
df = pd.read_csv("train_ctrUa4K.csv")
# drop nan values
df.dropna(inplace=True)
# instantiate labelencoder object
le = LabelEncoder()
# Categorical boolean mask
categorical_feature_mask = df.dtypes==object
# Get list of categorical column names
categorical_cols = df.columns[categorical_feature_mask].tolist()
# apply le on categorical feature columns
df[categorical_cols] = df[categorical_cols].apply(lambda col: le.fit_transform(col))
#split dataset into train and test
train, test = train_test_split(df, test_size=0.3, random_state=0)
x_train = train.drop('Loan_Status',axis=1)
y_train = train['Loan_Status']
x_test = test.drop('Loan_Status',axis=1)
y_test = test['Loan_Status']
model = RandomForestClassifier()
model.fit(x_train, y_train)
accuracy = model.score(x_test, y_test)
print("Accuracy: {:.2f}%".format(accuracy*100))Output:
Accuracy: 79.86%Một số tham số:
- n_estimators: Số lượng
decition trees(base models). Mặc định là 100 (đối với phiên bản scikit-learn từ 0.22) và 10 (đối với phiên bản < 0.22). - criterion: Chỉ ra hàm được sử dụng để quyết định hướng đi tại mỗi node của tree. Tham số này có thể nhận 1 trong 2 giá trị {"gini", "entropy"}. Giá trị mặc định là "gini".
- max_features: Số lượng
featuresđược sử dụng tại mỗi node để tìm đường đi tiếp theo. Một số giá trị thường được sử dụng là:- auto/sqrt: max_features = sqrt(n_features). Đây là giá trị mặc định.
- log2: max_features = log2(n_features).
- None: max_features = n_features.
- max_depth: Độ sâu của mỗi tree. Mặc định, các nodes sẽ được mở rộng tận khi tất cả các leaves chứa ít hơn
min_samples_splitmẫu (samples). - min_sample_split: Số lượng mẫu tối thiểu tại mỗi
leaf nodeđể có thể tiếp tục mở rộng tree. Giá trị mặc định là 2. - min_samples_leaf: Số lượng mẫu tối thiểu tại mỗi
leaf node. Mặc định là 1. - max_leaf_nodes: Số lượng
leaf nodetối đa của mỗi tree. Giá trị mặc định là không có giới hạn số lượng. - n_jobs: Số lượng jobs chạy song song. Mặc định là 1. Gán giá trị -1 để sử dụng tất cả các cores của hệ thống.
- random_state: Nếu tham số này được gán giá trị giống nhau mỗi lần gọi
RandomForestClassifierthì các dữ tập dữ liệu con sinh ra (một cách ngẫu nhiên) từ tập dữ liệu ban đầu sẽ giống nhau. Tham số này hữu ích khi cần so sánh các models với nhau.
2. Boosting techniques
2.1 AdaBoost
AdaBoost là thuật toán đơn giản nhất trong họ Boosting, nó cũng thường sử dụng decision tree để làm base model.
Thuật toán thực hiện như sau:
- Bước 1: Ban đầu, tất cả các mẫu dữ liệu được gán cho cùng một giá trị trọng số (weight).
- Bước 2: Lựa chọn ngẫu nhiên một tập dữ liệu con (tập S) từ tập dữ liệu ban đầu (tập D) và train
decition treemodel trên tập dữ liệu con này. - Bước 3: Sử dụng model đã trained, tiến hành dự đoán trên toàn tập D.
- Bước 4: Tính toán lỗi (error) bằng cách so sánh giá trị dự đoán và giá trị thực tế.
- Bước 5: Gán giá trị weight cao hơn cho những mẫu dữ liệu có error cao hơn.
- Bước 6: Lặp lại bước 2,3,4,5 đến khi error không đổi hoặc số lượng tốí đa của
weak learnerđạt được.
Code mẫu cho bài toán classification:
#importing important packages
import pandas as pd
import numpy as np
from sklearn import tree
from sklearn.ensemble import AdaBoostClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
#reading the dataset
df = pd.read_csv("train_ctrUa4K.csv")
# drop nan values
df.dropna(inplace=True)
# instantiate labelencoder object
le = LabelEncoder()
# Categorical boolean mask
categorical_feature_mask = df.dtypes==object
# Get list of categorical column names
categorical_cols = df.columns[categorical_feature_mask].tolist()
# apply le on categorical feature columns
df[categorical_cols] = df[categorical_cols].apply(lambda col: le.fit_transform(col))
#split dataset into train and test
train, test = train_test_split(df, test_size=0.3, random_state=0)
x_train = train.drop('Loan_Status',axis=1)
y_train = train['Loan_Status']
x_test = test.drop('Loan_Status',axis=1)
y_test = test['Loan_Status']
model = AdaBoostClassifier(random_state=1)
model.fit(x_train, y_train)
accuracy = model.score(x_test, y_test)
print("Accuracy: {:.2f}%".format(accuracy*100))Kết quả:
Accuracy: 72.22%Đối với bài toán regression, thay AdaBoostClassifier bằng AdaBoostRegressor.
Một vài tham số quan trọng:
- base_estimator: Chỉ ra
weak learnerlà gì. Mặc định sử dụngdecition tree. - n_estimators: Số lượng của
weak learners. Mặc định là 50. - learning_rate: Điều chỉnh mức độ
đóng gópcủa mỗiweak learnerđến kết quả cuối cùng. - random_state: Nếu tham số này được gán giá trị giống nhau mỗi lần gọi
AdaBoostClassifierthì các dữ tập dữ liệu con sinh ra (một cách ngẫu nhiên) từ tập dữ liệu ban đầu sẽ giống nhau. Tham số này hữu ích khi cần so sánh các models với nhau.
2.2 Gradient Boosting (GBM)
Để giúp mọi người dễ hình dung, mình sẽ trình bày ý tưởng của GBM thông qua ví dụ sau:
Cho bảng dữ liệu bên dưới:
| ID | Married | Gender | City | Monthly Income | Age (target) |
|---|---|---|---|---|---|
| 1 | Y | F | Hanoi | 51.000 | 35 |
| 2 | N | M | HCM | 25.000 | 24 |
| 3 | Y | F | Hanoi | 70.000 | 38 |
| 4 | Y | M | HCM | 53.000 | 30 |
| 5 | N | M | Hanoi | 47.000 | 33 |
Bài toán đạt ra là cần dự đoán tuổi dựa trên các input features: Tình trạng hôn nhân, giới tính, thành phố sinh sống, thu nhập hàng tháng.
- Bước 1: Train
decition treemodel thứ nhất trên tập dữ liệu bên trên. - Bước 2: Tính toán lỗi dựa theo sai số giữa giá trị thưc tế và giá trị dự đoán.
| ID | Married | Gender | City | Monthly Income | Age (target) | Age (prediction 1) | Error 1 |
|---|---|---|---|---|---|---|---|
| 1 | Y | F | Hanoi | 51.000 | 35 | 32 | 3 |
| 2 | N | M | HCM | 25.000 | 24 | 32 | -8 |
| 3 | Y | F | Hanoi | 70.000 | 38 | 32 | 6 |
| 4 | Y | M | HCM | 53.000 | 30 | 32 | -2 |
| 5 | N | M | Hanoi | 47.000 | 33 | 32 | 1 |
- Bước 3: Một
decition treemodel thứ 2 được tạo, sử dụng cùnginput featuresvới model trước đó, nhưngtargetlàError 1. - Bước 4: Giá trị dự đoán của model thứ 2 được cộng với giá trị dự đoán của model thứ nhất.
| ID | Age (target) | Age (prediction 1) | Error 1 (new target) | Prediction 2 | Combine (Pred1+Pred2) |
|---|---|---|---|---|---|
| 1 | 35 | 32 | 3 | 3 | 35 |
| 2 | 24 | 32 | -8 | -5 | 27 |
| 3 | 38 | 32 | 6 | 3 | 35 |
| 4 | 30 | 32 | -2 | -5 | 27 |
| 5 | 33 | 32 | 1 | 3 | 35 |
- Bước 5: Giá trị kết hợp bở bước 3 coi như là giá trị dự đoán mới. Ta tính lỗi (Error 2) dựa trên sai số giữa giá trị này và giá trị thực teses.
| ID | Age (target) | Age (prediction 1) | Error 1 (new target) | Prediction 2 | Combine (Pred1+Pred2) | Error 2 |
|---|---|---|---|---|---|---|
| 1 | 35 | 32 | 3 | 3 | 35 | 0 |
| 2 | 24 | 32 | -8 | -5 | 27 | -3 |
| 3 | 38 | 32 | 6 | 3 | 35 | 3 |
| 4 | 30 | 32 | -2 | -5 | 27 | 3 |
| 5 | 33 | 32 | 1 | 3 | 35 | -3 |
- Bước 6: Lặp lại bước 2-5 ho đến khi số lượng
weak learnerđạt được hoặc giá trị lỗi không đổi.
Code ví dụ cho bài toán classification:
#importing important packages
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import tree
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
#reading the dataset
df = pd.read_csv("train_ctrUa4K.csv")
# drop nan values
df.dropna(inplace=True)
# instantiate labelencoder object
le = LabelEncoder()
# Categorical boolean mask
categorical_feature_mask = df.dtypes==object
# Get list of categorical column names
categorical_cols = df.columns[categorical_feature_mask].tolist()
# apply le on categorical feature columns
df[categorical_cols] = df[categorical_cols].apply(lambda col: le.fit_transform(col))
#split dataset into train and test
train, test = train_test_split(df, test_size=0.3, random_state=0)
x_train = train.drop('Loan_Status',axis=1)
y_train = train['Loan_Status']
x_test = test.drop('Loan_Status',axis=1)
y_test = test['Loan_Status']
model = GradientBoostingClassifier(learning_rate=0.01,random_state=1)
model.fit(x_train, y_train)
accuracy = model.score(x_test, y_test)
print("Accuracy: {:.2f}%".format(accuracy*100))Output:
Accuracy: 78.47%Đối với bài toán regression, thay GradientBoostingClassifier thành GradientBoostingRegressor.
Một số tham số quan trọng:
- min_sample_split: Số lượng mẫu tối thiểu tại mỗi
leaf nodeđể có thể tiếp tục mở rộng tree. Giá trị mặc định là 2. - min_samples_leaf: Số lượng mẫu tối thiểu tại mỗi
leaf node. Mặc định là 1. - max_depth: Độ sâu của mỗi tree. Nên xem xét tham số này khi tuning model. Giá trị mặc định là 3.
- max_features: Số lượng tối đa
featuresxem xét khi tìm đường mở rộng tree. Những features này được chọn ngẫu nhiên.
2.3 XGBoost
XGBoost (extreme Gradient Boosting) là phiên bản cải tiến của Gradient Boosting. Ưu điểm vượt trội của nó được chứng minh ở các khía cạnh:
-
Tốc độ xử lý
- XGBoost thực hiện tinh toán song song nên tốc độ xử lý có thể tăng gấp 10 lần so với GBM. Ngoài ra, XGboost còn hỗ trợ tính toán trên Hadoop.
-
Overfitting
- XGBoost áp dụng cơ chế
Regularizationnên hạn chế đáng kể hiệ tượng Overfitting (GBM không có regularization).
- XGBoost áp dụng cơ chế
-
Sự linh hoạt
- XGboost cho phép người dùng sử dụng hàm tối ưu và chỉ tiêu đánh giá của riêng họ, không hạn chế ở những hàm cung cấp sẵn.
-
Xử lý
missing value- XGBoost bao gồm cơ chế tự động xử lý
missing valuebên trong nó. Vì thế, có thể bỏ qua bước này khi chuẩn bị dữ liệu cho XGBoost.
- XGBoost bao gồm cơ chế tự động xử lý
-
Tự động cắt tỉa
- Tính năng
tree pruninghộ trợ việc tự độngbỏ quanhững leaves, nodes không mang giá trị tích cực trong quá trình mở rộng tree.
- Tính năng
Chính vì những ưu điểm đó mà hiệu năng của XGBoost tăng lên đáng kể so với các thuật toán ensemble learning khác. Nó được sử dụng ở hầu hết các cuộc thi trên Kaggle cũng như Hackathons.
Code ví dụ cho bài toán classification:
#importing important packages
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import tree
import xgboost as xgb
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
#reading the dataset
df = pd.read_csv("train_ctrUa4K.csv")
# drop nan values
df.dropna(inplace=True)
# instantiate labelencoder object
le = LabelEncoder()
# Categorical boolean mask
categorical_feature_mask = df.dtypes==object
# Get list of categorical column names
categorical_cols = df.columns[categorical_feature_mask].tolist()
# apply le on categorical feature columns
df[categorical_cols] = df[categorical_cols].apply(lambda col: le.fit_transform(col))
#split dataset into train and test
train, test = train_test_split(df, test_size=0.3, random_state=0)
x_train = train.drop('Loan_Status',axis=1)
y_train = train['Loan_Status']
x_test = test.drop('Loan_Status',axis=1)
y_test = test['Loan_Status']
model = xgb.XGBClassifier(random_state=1, eta=0.01)
model.fit(x_train, y_train)
accuracy = model.score(x_test, y_test)
print("Accuracy: {:.2f}%".format(accuracy*100))Kết quả:
Accuracy: 82%Đối với vài toán regression, sử dụng XGBRegressor thay vì XGBClassifier.
Một số tham số quan trọng:
- n_thread: Số lượng cores của hê thống được sử dụng để chạy model. Giá trị mặc định là -1, XGBoost sẽ tự động phát hiện và sử dụng tất cả các cores.
- eta: Tương tự
learning_ratetrong GBM. Giá trị mặc định là 0.3. - max_depth: Độ sâu tối đa của
decision tree. Giá trị mặc định là 6. - colsample_bytree: Tương tự
max_featurescủa GBM. - lambda: L2 regularization. Giá trị mặc định là 1.
- alpha: L1 regularization. Giá trị mặc định là 0.
2.4 Light GBM
Tại sao chúng ta vẫn cần thuật toán này khi mà ta đã có XGBoost rất mạnh mẽ rồi?
Sự khác nhau nằm ở kích thước của dữ liệu huấn luyện. Light GBM đánh bại tất cả các thuật toán khác khi tập dataset có kích thước cực lớn. Thực tế chứng minh, nó cần ít thời gian đê xử lý hơn trên tập dữ liệu này (Có lẽ vì thế mà có chứ light - ánh sáng). Nguyên nhân sâu xa của sự khác biệt này nằm ở cơ chế làm viêc của Light GBM. Trong khi các thuật toán khác sử dụng cơ chế level-wise thì nó lại sử dụng leaf-wise.
Hình dưới đây minh họa sự khác nhau giữa 2 cơ chế level-wise và leaf-wise:
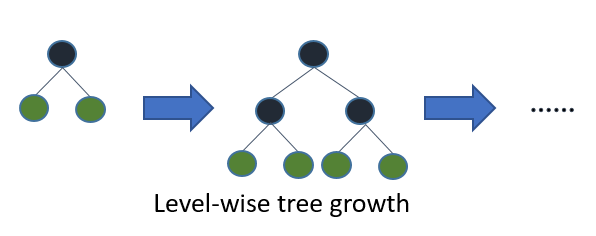
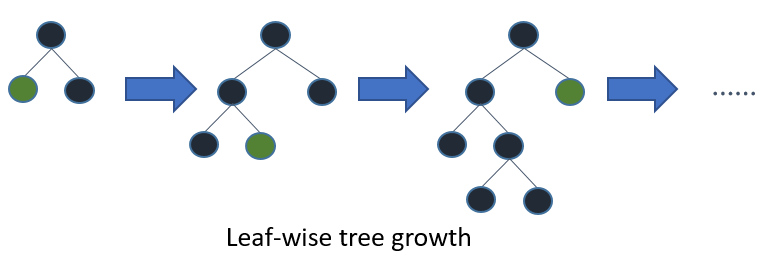
Như chúng ta thấy, leaf-wise chỉ mở rộng tree theo 1 trong 2 hướng so với cả 2 hướng của level-wise, tức là số lượng tính toán của Light GBM chỉ bằng 1/2 so với XGBoost.
Code ví dụ cho bài toán classifier:
#importing important packages
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import tree
import lightgbm as lgb
from sklearn.preprocessing import LabelEncoder
#reading the dataset
df = pd.read_csv("train_ctrUa4K.csv")
# drop nan values
df.dropna(inplace=True)
# instantiate labelencoder object
le = LabelEncoder()
# Categorical boolean mask
categorical_feature_mask = df.dtypes==object
# Get list of categorical column names
categorical_cols = df.columns[categorical_feature_mask].tolist()
# apply le on categorical feature columns
df[categorical_cols] = df[categorical_cols].apply(lambda col: le.fit_transform(col))
#split dataset into train and test
train, test = train_test_split(df, test_size=0.3, random_state=0)
x_train = train.drop('Loan_Status',axis=1)
y_train = train['Loan_Status']
x_test = test.drop('Loan_Status',axis=1)
y_test = test['Loan_Status']
model = lgb.LGBMClassifier()
model.fit(x_train, y_train)
accuracy = model.score(x_test, y_test)
print("Accuracy: {:.2f}%".format(accuracy*100))Trong trường hợp regression, sử dụng LGBMRegressor thay cho LGBMClassifier.
Một số tham số quan trọng:
- num_leaves: Số lượng leaves tối đa trên mỗi node. Giá trị mặc định là 31
- max_depth: Độ sâu tối đa của mỗi tree. Mặc định là không có giới hạn.
- learing_rate:
learning ratecủa mỗi tree. Mặc định là 0.1. - n_estimators: Số lượng
weak learners. Mặc định là 100. - n_jobs: Số lượng cores của hê thống được sử dụng để chạy model. Giá trị mặc định là -1, XGBoost sẽ tự động phát hiện và sử dụng tất cả các cores.
2.5 CatBoost
Khi làm việc với tập dữ liệu mà có số lượng lớn input features kiểu categorical, nếu chúng ta áp dụng one-hot encoding thì số chiều dữ liệu sẽ tăng lên rất nhanh (theo hàm mũ e).
CatBoost ra đời chính là để gánh vác sứ mệnh giải quyết những bài toán như vậy (CatBoost = Categories + Boosting). Khi làm việc với CatBoost, chúng ta không cần thực hiện one-hot encoding.
Code ví dụ cho classification:
# importing required libraries
import pandas as pd
import numpy as np
from catboost import CatBoostClassifier
from sklearn.metrics import accuracy_score
# read the train and test dataset
train_data = pd.read_csv('train-data.csv')
test_data = pd.read_csv('test-data.csv')
# Now, we have used a dataset which has more categorical variables
# hr-employee attrition data where target variable is Attrition
# seperate the independent and target variable on training data
train_x = train_data.drop(columns=['Attrition'],axis=1)
train_y = train_data['Attrition']
# seperate the independent and target variable on testing data
test_x = test_data.drop(columns=['Attrition'],axis=1)
test_y = test_data['Attrition']
# find out the indices of categorical variables
categorical_var = np.where(train_x.dtypes != np.float)[0]
model = CatBoostClassifier(iterations=50)
# fit the model with the training data
model.fit(train_x,train_y,cat_features = categorical_var,plot=False)
# predict the target on the train dataset
predict_train = model.predict(train_x)
# Accuray Score on train dataset
accuracy_train = accuracy_score(train_y,predict_train)
print('\naccuracy_score on train dataset : {:.2f}%'.format(accuracy_train*100))
# predict the target on the test dataset
predict_test = model.predict(test_x)
# Accuracy Score on test dataset
accuracy_test = accuracy_score(test_y,predict_test)
print('\naccuracy_score on test dataset : {:.2f}%'.format(accuracy_test*100))Kết quả:
accuracy_score on train dataset : 91.41%
accuracy_score on test dataset : 86.05%Thay CatBoostRegressor cho CatBoostClassifier trong bài toán regression.
Một số tham số quan trọng:
- loss_function: Định nghĩa
loss_functionsử dụng để training model. - iterations: Số lượng
weak learner. - learning_rate: Learning rate của mỗi tree.
- depth: Độ sâu của mỗi tree.
3. Kết luận
Chúng ta đã cùng nhau đi qua 2 phần khá dài để tìm hiểu về Ensemble Learning. Rất nhiều khía cạnh đã được bàn bạc và kèm theo code ví dụ. Hi vọng các bạn đã có cái nhìn rõ hơn về Ensemble Learning. Trong các bài tiếp theo, mình sẽ đi sâu hơn về XGBoost, một thuật toán mạnh mẽ, chiến thắng trong hầu như mọi cuộc thi Kaggle. Hãy đón đọc!
Toàn bộ source code của bài này các bạn có thể tham khảo trên github cá nhân của mình tại github.
Xem bài viết gốc tại đây.





Vui lòng đăng nhập để bình luận.