


Sử dụng Index trong MySQL: Phần 1- Các loại index và cách đánh index
Một trong những vấn đề mà mình nghĩ là tốn nhiều thời gian, công sức của lập trình viên đó là việc nâng cao performance cho hệ thống.
Sẽ không có vấn đề gì nếu hệ thống chỉ có số users và lượng data không quá lớn, nhưng nếu ngược lại việc tối ưu hoá các query với database sẽ là then chốt để optimize performance cho hệ thống.
Trong bài viết này mình sẽ giới thiệu về việc đánh index cho các table qua đó tăng performance cho các câu lệnh query.
Ⅰ. Index là gì?
Index là một cấu trúc dữ liệu giúp xác định nhanh chóng các records trong table.
Hiểu một cách đơn giản thì nếu không có index thì SQL phải scan toàn bộ table để tìm được các records có liên quan. Dữ liệu càng lớn, tốc độ query sẽ càng chậm.
Ⅱ. Pros & Cons khi đánh index.
※Ưu điểm
Ưu điểm của index là tăng tốc độ tìm kiếm records theo câu lệnh WHERE.
Không chỉ giới hạn trong câu lệnh SELECT mà với cả xử lý UPDATE hay DELETE có điều kiện WHERE.
※Nhược điểm
Khi sử dụng index thì tốc độ của những xử lý ghi dữ liệu (Insert, Update, Delete) sẽ bị chậm đi.
Vì ngoài việc thêm hay update thông tin data thì MYSQL cũng cần update lại thông tin index của bảng tương ứng.
Tốc độ xử lý bị chậm đi cũng tỷ lệ thuận với số lượng index được xử dụng trong bảng.
Do vậy với những table hay có xử lý insert, update hoặc delete và cần tốc độ xử lý nhanh thì không nên được đánh index.
Ngoài ra việc đánh index cũng sẽ tốn resource của server như thêm dung lượng cho CSDL.
Ⅲ.Các kiểu index
MySQL cung cấp 3 kiểu index khác nhau cho data đó là B-Tree, Hash và R-Tree index.
Do R-Tree được sử dụng cho các loại dữ liệu hình học không gian Spatial data và thường ít khi gặp phải nên bài viết này chúng ta sẽ tập chung vào 2 loại index là B-Tree và Hash.
1. B-Tree index
Thông thường khi nói đến index mà không chỉ rõ loại index thì default là sẽ sử dụng B-Tree index.
Cú pháp:
|
1
2
3
4
5
6
|
// Create index
CREATE INDEX id_index ON table_name (column_name[, column_name…]) USING BTREE;
// Or
ALTER TABLE table_name ADD INDEX id_index (column_name[, column_name…])
//Drop index
DROP INDEX index_name ON table_name
|
Các đặc điểm của B-Tree Index:
– Dữ liệu index được tổ chức và lưu trữ theo dạng tree, tức là có root, branch, leaf.
※Cách sắp xếp không phải theo dạng cây tìm kiếm nhị phân – Binary search tree vì số lá là mỗi node không bị giới hạn là 2.
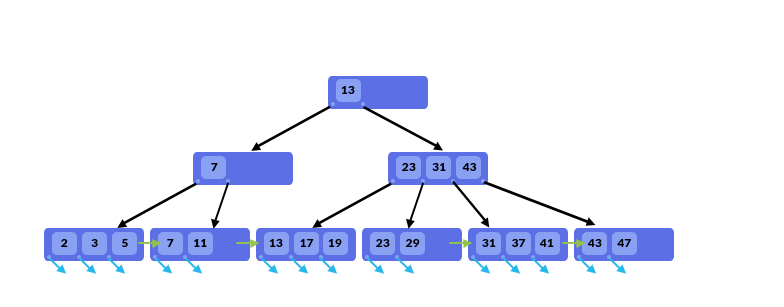
– Giá trị của các node được tổ chức tăng dần từ trái qua phải.
– B-Tree index được sử dụng trong các biểu thức so sánh dạng: =, >, >=, <, <=, BETWEEN và LIKE. ⇒ Có thể tối ưu tốt cho câu lệnh ORDER BY
– Khi truy vấn dữ liệu thì CSDL sẽ không scan dữ liệu trên toàn bộ bảng để tìm dữ liệu, việc tìm kiếm trong B-Tree là 1 quá trình đệ quy, bắt đầu từ root node và tìm kiếm tới branch và leaf, đến khi tìm được tất cả dữ liệu – thỏa mãn với điều kiện truy vấn thì mới dùng lại.
2. Hash index
Hash index dựa trên giải thuật Hash Function (hàm băm). Tương ứng với mỗi khối dữ liệu (index) sẽ sinh ra một bucket key(giá trị băm) để phân biệt.
Cú pháp:
|
1
2
3
4
|
// Create index
CREATE INDEX id_index ON table_name (column_name[, column_name…]) USING HASH;
// Or
ALTER TABLE table_name ADD INDEX id_index (column_name[, column_name…]) USING HASH;
|
Các đặc điểm của Hash Index:
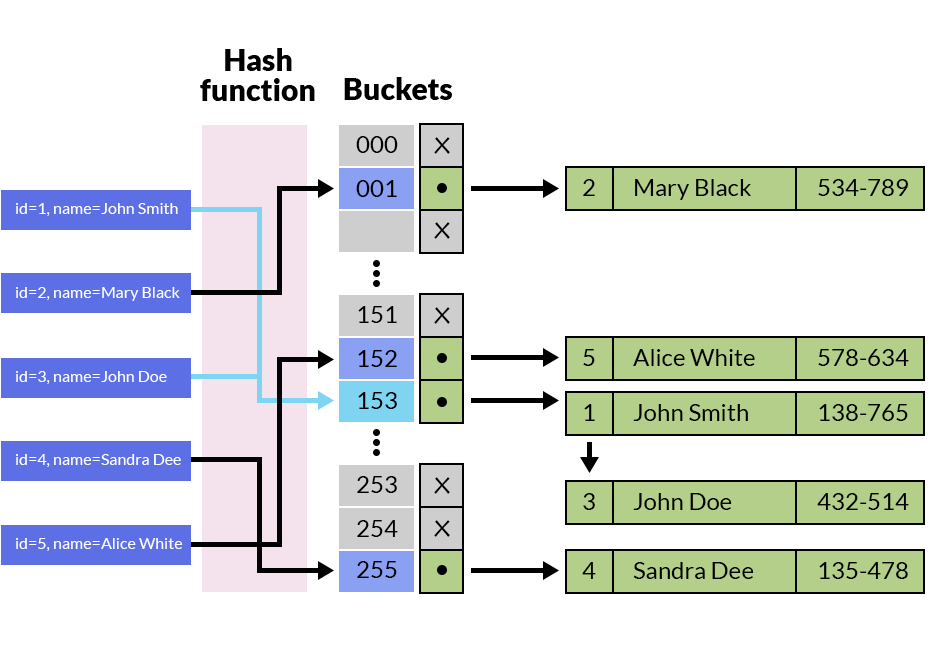
– Khác với B-Tree, thì Hash index chỉ nên sử dụng trong các biểu thức toán tử là = và <>. Không sử dụng cho toán từ tìm kiếm 1 khoảng giá trị như > hay < .
– Không thể tối ưu hóa toán tử ORDER BY bằng việc sử dụng Hash index bởi vì nó không thể tìm kiếm được phần từ tiếp theo trong Order.
– Hash có tốc độ nhanh hơn kiểu B-Tree.
3. Các kiểu index tương ứng với Storage Engine
Việc chọn index theo kiểu B-Tree hay Hash ngoài yếu tố về mục đích sử dụng index thì nó còn phụ thuộc vào việc Storage Engine có hỗ trợ loại index đó hay không.
| Storage Engine | Các kiểu index được hỗ trợ |
|---|---|
| InnoDB | BTREE |
| MyISAM | BTREE |
| MEMORY/HEAP | HASH, BTREE |
| NDB | HASH, BTREE |
Ⅳ.Cách đánh index
1. Đánh index một trường
Đây là cách khá thông thường khi chúng ta lựa chọn 1 column được sử dụng nhiều khi tìm kiếm và đánh index cho nó.
Nhưng có một lưu ý đó là nếu số lượng giá trị unique hay giá trị khác NULL trong column đó quá thấp so với tổng số records của bảng thì việc đánh index lại không có ý nghĩa lắm.
Sẽ khá là kỳ lạ nếu những trường như gender hay age lại được đánh index ngay cả khi được tìm kiếm nhiều.
2. Đánh index nhiều trường (B-Tree Index)
Với trường hợp đánh index trên nhiều columns thì index chỉ có hiệu quả khi search theo thứ tự các trường của index.
Giả sử có table Customer:
|
1
2
3
4
5
|
CREATE TABLE Customer(
last_name varchar(50) not null,
first_name varchar(50) not null,
dob date not null,
key(last_name, first_name, dob) );
|
Thứ tự cột index trong câu lệnh trên là last_name, first_name và dob.
Vậy nếu điều kiện tìm kiếm như dưới thì index sẽ được sử dụng.
|
1
|
SELECT * FROM Customer WHERE last_name=’Peter’ AND first_name=’Smith’
|
Nhưng trong những trường hợp sau index sẽ không được sử dụng:
|
1
2
|
SELECT * FROM Customer WHERE first_name=’Smith’ AND bod=’1992/04/11’;
SELECT * FROM Customer WHERE first_name=’Smith’ AND last_name=’Peter’
|
Như vậy nếu bạn đánh index cho nhiều columns thì việc quan trọng nhất đó là search theo thứ tự các columns được đánh index
và đảm bảo rằng column đầu tiên được đánh index sẽ luôn nằm trong điều kiện tìm kiếm của bạn.
Kết
Như vậy chúng ta đã đi khái quát qua các khái niệm về index, các loại index cũng như cách đánh index rồi.
Bài tiếp theo mình sẽ đi sâu hơn và việc phân tích performance của các câu lệnh sql để xem việc chúng ta đánh index có thực sự hiệu quả không.
Nguồn tham khảo
https://www.vertabelo.com/blog/technical-articles/all-about-indexes-part-2-mysql-index-structure-and-performance
https://qiita.com/ysks-y/items/bba52e4a7eba82a715be





Vui lòng đăng nhập để bình luận.