


Lời nói đầu:
- Chào các bạn, lại là mình đây – Duy Nam – Thành viên Group 1 VTI Japan. Hôm nay mình xin tiếp tục seri về Amazon Elasticsearch Service Best Practice.
Bài viết của mình chia ra làm 4 chương chính:
Chương 1: Kiến trúc tổng quan của Amazon ES
- Kiến trúc tổng quan của Amazon ES
- Giới thiệu vai trò của Master Node, Data Node, Shard
- Lưu ý khi đặt Amazon ES vào trong VPC
Chương 2: Sizing Amazon ES
- Tính toán dữ liệu đưa vào Amazon ES
- Tính toán số Shard cần thiết cho Amazon ES
- Lựa chọn instance type phù hợp cho Master Node và Data Node
Chương 3: Backup và Monitoring ES
- Giới thiệu vai trò của Automated Backup và Manual Backup
- Restore Data của Amazon ES, Migration Data từ Elasticseach on EC2
- Giới thiệu các Metric cần theo dõi của Amazon ES
Chương 4: Một vài chia sẻ từ kinh nghiệm thực tế
- Giới thiệu về Index, Document, Type
- Một vài những câu query cơ bản của Elasticseach
- Một vài option khác gặp trong thực tế
Chương 4: Một vài chia sẻ từ kinh nghiệm thực tế
4.1 Khái niệm về Index, Document và Type
-
Đến với Elasticseach chúng ta có các khái niệm như sau:
- Cluster: Một tập hợp các Nodes (servers) chứa tất cả các dữ liệu nhằm đảm bảo tính tin cậy và sẵn dùng
- Master Node: Kiểm soát trạng thái của Elasticseach Cluster
- Data Node: Server duy nhất chứa dữ liệu và tham gia vào tập hợp cluster’s indexing and querying.
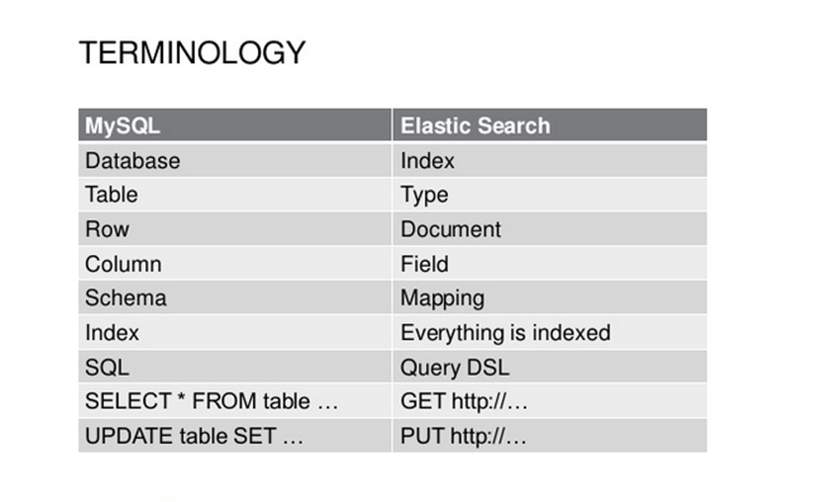
- Index: Nơi chứa dữ liệu của ES (tương đương với khái niệm một database trong cơ sở dữ liệu quan hệ)
- Type: là 1 tập các document cùng loại (tương đương với khái niệm table trong cơ sở dữ liệu quan hệ)
- Document: Một JSON object với một số dữ liệu, đây là một đơn vị thông tin trong Elasticsearch (tương đương khái niệm row trong table của cơ sở dữ liệu quan hệ)
- Shards: Tập con các documents của 1 Index. Một Index có thể được chia thành nhiều shard, mỗi shard cũng có thể coi là một index có thể được truy cập trực tiếp giúp tính toán, tìm kiếm 1 cách song song.
-
Các bạn có thể tham khảo bảng mapping sau:

4.2 Một số trường hợp nên sử dụng ES:
- Tìm kiếm text thông thường – Searching for pure text (textual search)
- Tìm kiếm text và dữ liệu có cấu trúc – Searching text and structured data (product search by name + properties)
- Tổng hợp dữ liệu – Data aggregation
- Tìm kiếm theo tọa độ – Geo Search
- Lưu trữ dữ liệu theo dạng JSON – JSON document storage
4.3 Tạo một Index Sample:
- Như các bài trước mình có đề cập, sau khi tiến hành sizing ES chúng ta đủ cơ sở để tạo Index rồi.
- Thông tin Index sẽ được quy định trong một file JSON sau:
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1,
"analysis": {
"analyzer": {
"kuromoji_normalize": {
"tokenizer": "kuromoji_tokenizer",
"char_filter": [
"icu_normalizer",
"kuromoji_iteration_mark"
],
"filter": [
"kuromoji_baseform",
"kuromoji_part_of_speech",
"ja_stop",
"kuromoji_number",
"kuromoji_stemmer"
]
}
}
}
}
}
4.3.1 Tạo một Index Sample:
-
Ví dụ sau khi bạn tạo ES sẽ có:
- ES_DOMAIN=https://sample.esdomain.region.es.amazonaws.com
- USER=hello_es_user
- PASS=hello_es_pass
-
curl -H "Content-Type: application/json" -u "${USER}:${PASS}" -XPUT "${ES_DOMAIN}/sample" -d @setting.json- Các bạn có thể dùng thao tác trực tiếp với Kibana, nhưng mình quen dùng comand line hơn
- Dùng câu lệnh PUT để tạo index và đưa dữ liệu mới vào
- sample: chính là index các bạn đã tạo ra
4.3.2 Tạo một Type, Document:
curl -H 'Content-Type: application/json' -u "${USER}:${PASS}" -XPUT "${ES_DOMAIN}/sample/external/1?pretty" -d '{"name": "Hello World"}'- external: chúng ta đã tạo 1 type có tên là external
- 1: chính là document đầu tiên được tạo ra
4.3.3 Một số quyery cơ bản khác:
-
GET document:
curl -u "${USER}:${PASS}" -XGET "${ES_DOMAIN}/sample/external/1?pretty"
-
POST document:
curl -H 'Content-Type: application/json' -u "${USER}:${PASS}" -XPOST "${ES_DOMAIN}/sample/external/1/_update?pretty" -d ' { "doc": { "name": "Jane Doe", "age": 20 } }' -
DELETE document:
curl -H 'Content-Type: application/json' -u "${USER}:${PASS}" -XDELETE "${ES_DOMAIN}/sample/external/1?pretty"
-
GET thông tin toàn index:
curl -u "${USER}:${PASS}" -XGET "${ES_DOMAIN}/_cat/health?v"
4.4 Mở rộng ứng dụng:
- Đến đây mình tin các bạn có thể mở rộng tìm hiểu về ES rồi, trong Amazon ES còn nhiều option khác mình chưa có cơ hội chia sẻ hết được.
- Để tiết kiệm cost chúng ta có thể dùng UltraWarm Node hay sử dụng tenancy.
- Việc đặt ES trong VPC sẽ kiến việc Manual Snapshot trở nên phức tạp hơn, vì các bạn cần set thêm role cho các máy tạo backup.
…
Lời Kết
- Sau 4 bài viết mình đã có cơ hội giới thiệu về Best Practice của Amazon Elasticseach. Hi vọng qua 4 bài viết này các bạn có thêm kiến thức để tạo ra một Server Elasticseach hiệu quả cao nhất.
- Mong các bạn ủng hộ seri này của mình và hẹn các bạn ở các seri chia sẻ về Best Practice tiếp theo, có thể là EKS, ECS hoặc RDS nhỉ





Vui lòng đăng nhập để bình luận.