Chào mừng trở lại
Vui lòng đăng nhập để khám phá toàn bộ các bài viết hấp dẫn tại VTI Tech Blog
Vui lòng đăng nhập để khám phá toàn bộ các bài viết hấp dẫn tại VTI Tech Blog
 (+84) 24-7303-9996
(+84) 24-7303-9996
 vti.techblog@vti.com.vn
vti.techblog@vti.com.vn
Khám phá các góc nhìn công nghệ, chia sẻ kinh nghiệm và cập nhật xu hướng mới nhất từ những người trực tiếp tạo ra giải pháp tại VTI.

Trong một quy trình phát triển phần mềm, hình thức test phần mềm phổ biến là Manual Test (kiểm tra thủ công bằng tay). Ví dụ để test chức năng của form log in, một Manual Tester sẽ tự nhập tay username, password, click “log in”, xem kết quả đăng…
Chào các bạn mình là Hậu bên Group1 VJP. Dạo gần đây nghe người người nói về AWS Cloud, nhà nhà nói về AWS cloud, nhiều service xịn sò thật đấy nhưng toàn là dùng cho dự án của khách hàng thôi, có dịch vụ nào hữu dụng cho dân…

Hi Vtitans, Bài này ngắn lắm, mình chỉ share cái launch config để debug app của mình thôi. Do document hơi ít ví dụ nên mình nghĩ là có ích. Đây ạ: { "version": "0.2.0", "configurations": [ { "name": "Launch Package", "type": "go", "request": "launch", "mode": "debug", "program": "${workspaceFolder}/cmd/server/", "env":…
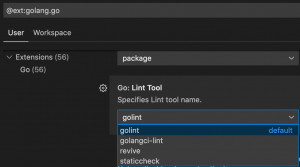
Hi Vtitans, Hôm nay mình trả lời câu hỏi "có nên sử dụng Golint" trong dự án của mình không. Mình nghĩ quyết định là dựa trên dự án, nhưng những thông tin đưa ra ở đây có giá trị tham khảo cho, ví dụ, một team đang cân nhắc…

Hi Vtitans, Do Golang có bước chuyển đổi lớn về cách quản lý dependencies (từ Go 11), rất nhiều project, library, framework và đặc biệt là documentation không cập nhật hoàn chỉnh ngay được, dẫn đến nhiều khi anh em coder phải loay hoay cả tiếng đồng hồ không xong…

Hi Vtitans, Hôm nay mình lộ bí mật đen tối là đôi khi mình blog trong bực bội đó. Nguyên là thấy code kì cục mà chưa được khách cho sửa, dev nào mà chẳng ấm ức. Tuy mình không biết code, mình cũng chẳng biết golang với toml gì…
Hi Vtitans, Một vấn đề với POJO: sau khi ta viết một POJO với một tá field, và cảm thấy mình đã sẵn sàng bind data vào nó, convert sang Json string để trả về cho một GET request, rồi phát hiện ra là Rest service của chúng ta mong…

Hi Vtitans, Trong một số tình huống, thay vì file dump của Postgres, bạn có trong tay bản back up của data directory và cần restore sang một server mới dựng. Sẽ phát sinh những câu hỏi như cần copy vào đâu và set permission như thế nào, bài này…
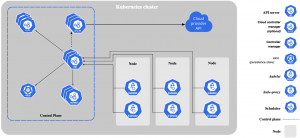
Hi Vtitans, Mình đang ngồi tính toán chi phí tạo cluster thứ hai trên GKE và phát hiện cluster thứ nhất được miễn phí. Bài này mình ghi lại các thông tin về cái vụ miễn phí này nhé. Phần nào của cost được miễn phí? Google gọi nó là…
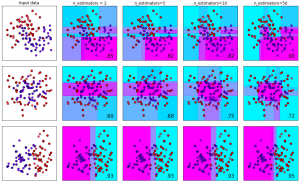
Ý tưởng cơ bản của thuật toán Gradient Boosting là lần lượt thêm các decision trees nối tiếp nhau. Tree thêm vào sau sẽ cố gắng giải quyết những sai sót của tree trước đó. Câu hỏi đặt ra là bao nhiêu trees (weak learner hay estimators) là đủ? Trong…
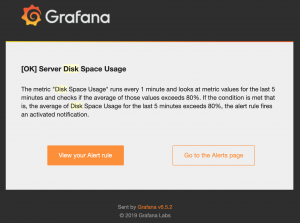
Hi Vtitans, Đây có thể là một câu hỏi phỏng vấn hay đấy! Do giảm thiểu chi phí, nhiều ổ cứng trên server chỉ có size minimum. Cỡ 10GB là đủ cho Linux EC2 và Google VM chạy web app rồi, nhưng với điều kiện là đã có ý thức…

Hi Vtitans, Ôi trời ơi, mỗi lần thử vọc cái gì mới trên con máy của mình là một lần chuẩn bị tâm lý phải fix issue gì đó trước khi chạy được một cái hello world! Đến mức thành quen, mình chả thèm nghĩ đến "set up chuẩn" nữa,…


Khám phá cơ chế nhuận bút khi đóng góp bài viết ngay tại đây!
Vui lòng đăng nhập để khám phá toàn bộ các bài viết hấp dẫn tại VTI Tech Blog
