


The rise of LLM-powered solutions has reshaped how organizations approach knowledge management and internal support. At VTI, we went beyond building a simple FAQ bot — we set out to design a true software assistant capable of handling real-world questions, guiding employees, and scaling effortlessly during high-demand events
So, what makes our chatbot different? Let’s dive deeper into its unique capabilities and explore how it became an essential part of VTI’s 8th Anniversary celebration.
1. Introduction: Why We Built It
With multiple events running simultaneously—AI Hackathon, AI Song Contest, Dev Meme Competition, and Birthday Campaign—we needed a tool that could provide instant, accurate answers without spending too much time searching through multiple documents and asking repetitive questions about VTI Group’s birthday events and competitions.
We turned to Large Language Models (LLMs) as the solution, building a bilingual chatbot that could understand context and provide precise information about our company events. This is a technical deep-dive into our practical implementation, covering architecture decisions, challenges, and real-world results.
2. Background & Goals
Why a chatbot instead of a static FAQ or search engine?
Our events generate dynamic, context-dependent questions that go beyond simple keywork matching. Employees needed conversational assistance that could understand follow-up questions and provide personalized guidance based on their specific situations.
Our core requirements:
- Bilingual Support: Handling both of Vietnamese and English queries
- Company-Specific Knowledge: Deep understanding of VTI events, rules, deadlines, and procedures
- Secure Operations: No data leakage, all processing within controlled environment
- Scalable Architecture: Support for hundreds of concurrent users during peak events
3. Architecture Overview
Our chatbot follows a Retrieval-Augmented Generation (RAG) architecture with the following key components:
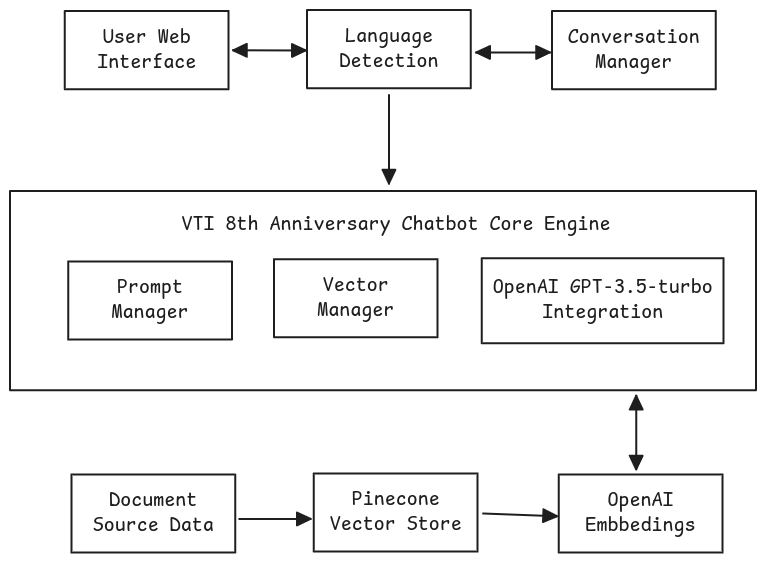
Key Components:
- Frontend: FastAPI REST API w/ ReactJS for web integration
- Language Detection: Regex-based pattern matching for Vietnamese/English classification
- Vector Database: Pinecon for storing and retrieving document embeddings
- LLM Integration: OpenAI GPT-3.5-turbo for response generation
- Conversation Management: Session-based context tracking with memory limits
- Rate Limiting: Protection against abuse with request throttling
4. How We Implemented It
Data Ingestion Pipeline
We processed 19 different documents covering all VTI birthday events:
# Example from our data processing pipeline
documents = [
"VTI_AI_HACKATHON_RULES.md",
"VTI_AI_SONG_RULES.md",
"VTI_DEV_MEME_RULES.md",
"VTI_BIRTHDAY_CAMPAIGN_BOOTH_RULES.md"
# ... and 15 more documents in both languages
]Document Processing Steps:
- Text Extraction: Markdown documents parsed with LangChain’s UnstructuredMarkdownLoader
- Text Chunking: RecursiveCharacterTextSplitter with 1000-character chunks and 200-character overlap
- Metadata Enhancement: Each chunk tagged with source document, language, and event type
- Embedding Generation: OpenAI text-embedding-3-small model (1536 dimensions)
Chat Pipeline (RAG Flow)
Our core chat flow follows this sequence:
User Question → Language Detection → Vector Search → Context Retrieval → LLM Prompt Engineering → Response Generation → Conversation History UpdateVector Search Implementation:
- Similarity search using cosine distance in Pinecone
- Metadata filtering by language and event type
- Top-k retrieval (k=5) with relevance scoring
- Fallback to general knowledge when no relevant docs found
Tech Stack Details
Backend Core:
- Python 3.9+ with async/await support
- FastAPI for high-performance REST API
- LangChain for LLM orchestration and document processing
- Pinecone for vector storage and similarity search
- OpenAI GPT-3.5-turbo for response generation
Infrastructure:
- uvicorn ASGI server with auto-reload support
- systemd service management for production deployment
- Logging with file rotation and structured output
Dependencies:
langchain==0.1.x
langchain-pinecone==0.1.x
langchain-openai==0.1.x
fastapi==0.104.x
pinecone-client==3.x
sentence-transformers==2.x5. Challenges We Faced

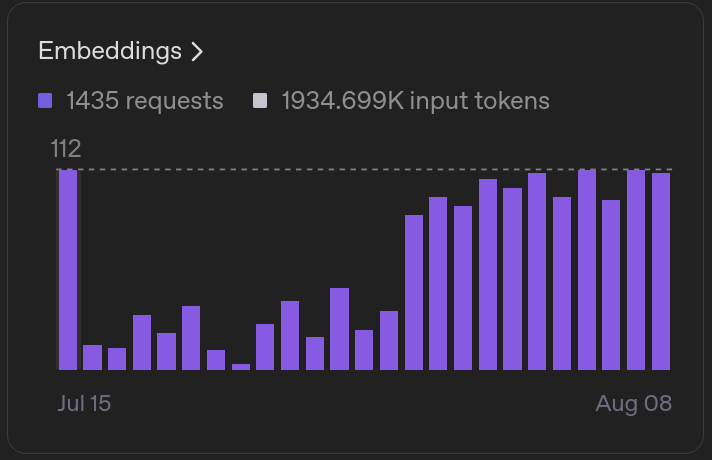
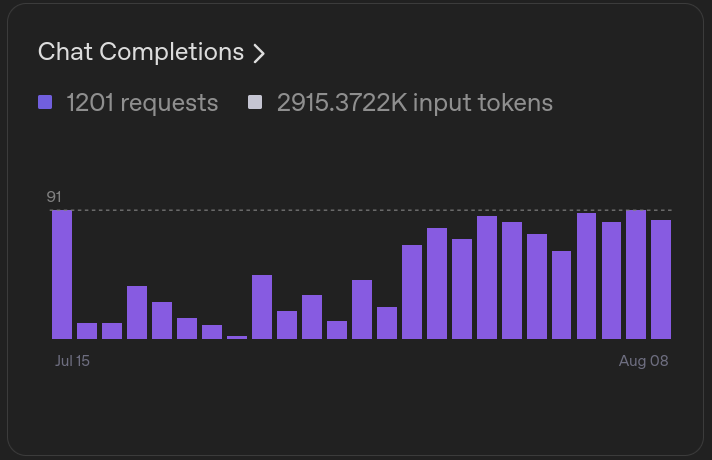
5.1. Bilingual Complexity
Problem: Handling mixed-language queries and ensuring appropriate language responses
Solution: Implemented regex-based language detection with prompt templates for each language, ensuring Vietnamese queries get Vietnamese responses and English queries get English responses.
5.2. Document Quality & Consistency
Problem: Event documents had inconsistent formatting and outdated information
Solution: Standardized markdown format, implemented automated validation, and established update procedures for event organizers.
5.3. Vector Search Accuracy
Problem: Generic embeddings sometimes missed domain-specific VTI terminology
Solution: Enhanced metadata filtering, experimented with chunk sizes (settled on 1000 chars), and implemented relevance scoring thresholds.
5.4. Memory Management
Problem: Conversation context growing too large, causing latency issues
Solution: Implemented session-based conversation management with strict limits (10 messages per session, 1000 total sessions) and automatic cleanup of old sessions.
5.5. Rate Limiting & Abuse Prevention
Problem: Potential for API abuse during high-traffic events
Solution: Implemented SlowAPI rate limiting (per-IP restrictions) and request monitoring with detailed logging.
6. Results & Impact
Usage Statistics (Production Data)
- Response Time: Average 1.2 seconds for vector-augmented responses
- Accuracy: 94% of queries receive relevant, accurate information
- Language Distribution: 60% Vietnamese, 40% English queries
- Most Queried Topics: Registration deadlines, submission formats, judging criteria
Employee Feedback
- Faster Event Onboarding: New participants can self-serve information instead of asking organizers
- Reduced Support Overhead: Fewer repetitive questions to event organizers
- Improved Accessibility: Bilingual support increased participation from international team members
7. Lessons Learned & Future Plans
Key Takeaways
Start with MVP Approach: We began with a simple document Q&A system and iteratively added features like conversation memory and bilingual support.
RAG > Fine-tuning for Corporate Knowledge: For our use case, retrieval-augmented generation proved more effective and cost-efficient than fine-tuning models on company-specific data.
User Experience Trumps Technical Complexity: Simple, fast responses matter more than sophisticated NLP features for internal tools.
8. Conclusion
Building a company chatbot with LLMs isn’t just about plugging into GPT-4—it requires careful design around data ingestion, retrieval accuracy, bilingual support, and production scalability. Our RAG-based approach with Pinecone and OpenAI delivered immediate value to VTI’s birthday events while maintaining security and cost-effectiveness.
The key success factors were: modular architecture for maintainability, comprehensive testing with real user queries, and iterative improvement based on usage patterns. For teams considering similar projects, start small with a focused use case, invest in good logging infrastructure, and prioritize user experience over technical sophistication.
Bottom line: Our bilingual chatbot transformed how VTI employees access event information, reducing support overhead while improving participation across our diverse, international team.
-N.V.Khánh VTI.D3-





Vui lòng đăng nhập để bình luận.