


Thư viện XGBoost được thiết kế để tận dụng tối đa sức mạnh của phần cứng hệ thống, bao gồm tất cả CPU cores và bộ nhớ. Trong bài viết này, ta sẽ cùng nhau tìm hiểu cách thiết lập một server trên AWS để train XGBoost model, sao cho vừa nhanh, vừa rẻ! 😀
Bài viết gồm 4 phần:
- Tạo tài khoản AWS
- Chạy AWS EC2 Instance
- Kết nối đến EC2 Instance và chạy code
- train XGBoost model
- Đóng AWS EC2 Instance
Chú ý quan trọng: Sẽ mất khoảng 1-2$ chi phí để sử dụng các dịch vụ của AWS trong bài viết này.
1. Tạo tài khoản AWS
(Nếu bạn đã có tài khoản AWS, hãy bỏ qua bước này!)
- Truy cập vào màn hình console của AWS. Tại đây ta có thể đăng nếu đã có tài khoản hoặc đăng ký tài khoản mới nếu chưa có.
- Bạn cần cung cấp một số thông tin cần thiết, và đặc biệt là phải có một thẻ credit còn hiệu lực để có thể tiến hành tạo tài khoản. Các công đoạn khác, hãy làm theo chỉ dần trên màn hình.
2. Chạy AWS EC2 Instance
Chúng ta sẽ sử dụng dịch vụ EC2 để chạy XGBoost.
- Đăng nhập vào AWS console. Sau khi đăng nhập thành công, danh sách các dịch vụ của AWS sẽ hiển thị.
- Chọn EC2.
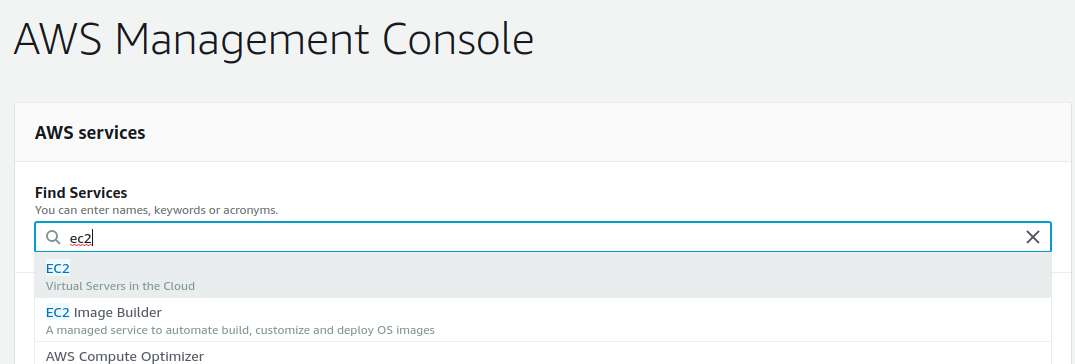
- Click vào nút
Launch EC2 Instance. - Click vào
Community AMIs
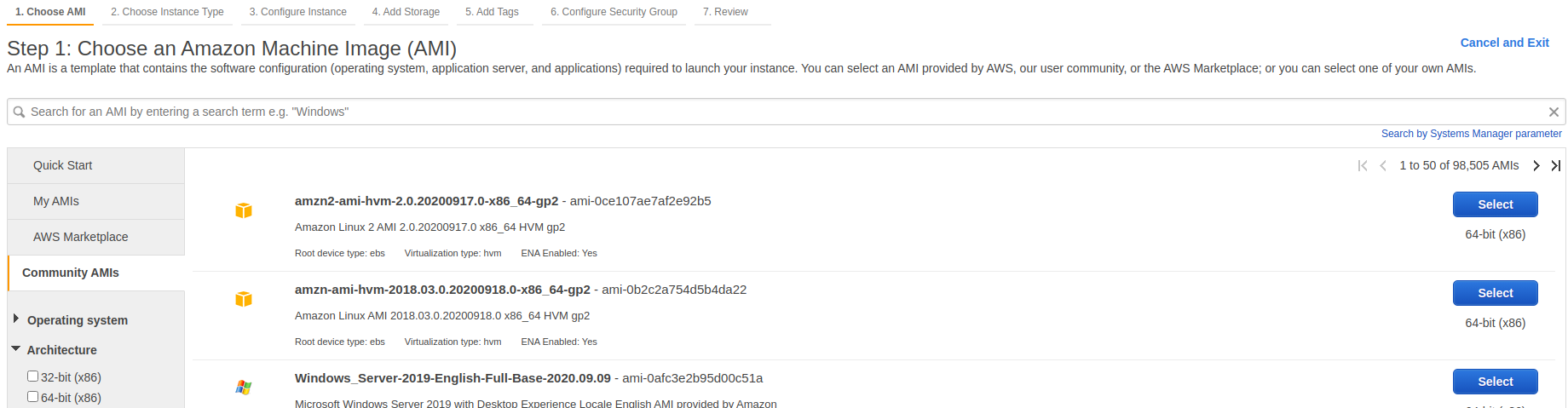
- Nhập
ami-1c40bf7dvàoSearch community AMIsvà chọnSelect.

- Chọn EC2 Instance type là r4.8xlarge (32 cores CPU).
ClickReview and Launch. - Click
Launch. - Chọn
Create a new key pair, điền tên củakeylàxgboost-key và clickDownload Key Pair`.
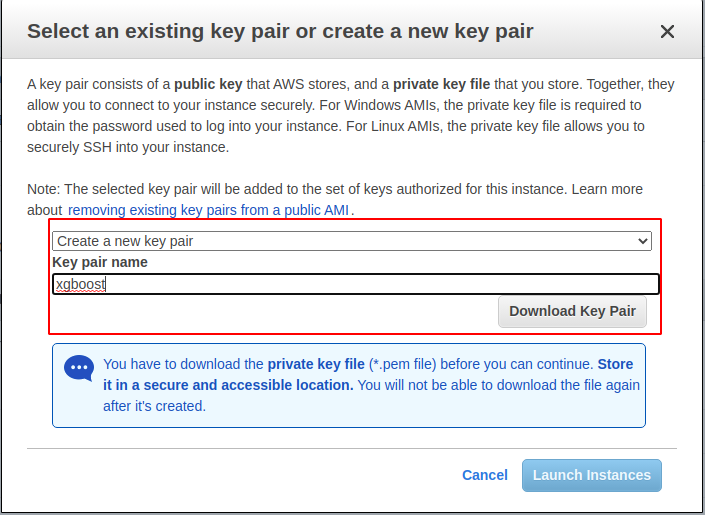
Lưu file key vào máy tính ở local, sau đó click Launch EC2 Instances.
- Click
View EC2 Instances.
Chờ khoảng 3 phút và kiểm tra trạng thái của EC2 Instance.

Nếu trạng thái là Running thì tức là đã tạo EC2 Instance thành công.
Ta cũng để ý thấy địa chỉ public IP của EC2 Instance là: 54.92.106.10. Tiếp theo ta sẽ sử dụng địa chỉ này để kết nối đến EC2 Instance từ localhost thông qua giao thức SSH.
3. Kết nối đến EC2 Instance và chạy code
3.1 Kết nối đến EC2 Instance qua giao thức ssh
- Trên máy tính local (mình dùng Ubuntu), mở cửa sổ Terminal và gõ lệnh:
$ cd Documents #Thư mục chứa key file $ chmod 600 xgboost-key.pem $ ssh -i xgboost.pem fedora@54.92.106.10Nếu đây là lần đầu kết nối đến EC2 Instance, sẽ có 1 cảnh báo xuất hiện. Gõ
yes.
Nếu kết nối thành công, màn hình Terminal sẽ xuất hiện như sau:

- Kiểm ra số lượng CPU cores
$cat /proc/cpuinfo | grep processor | wc -lKết quả:
323.2 Cài đặt các thư viện cần thiết
- Cài đặt GCC, Python và SciPy
sudo dnf install gcc gcc-c++ make git unzip python python3-numpy python3-scipy python3-scikit-learn python3-pandas python3-matplotlib - Cài đặt Cmake
XGBoost yêu cầu cmake >= 3.13. Nếu bạn cài bằng bằng lệnh dnf install cmake thì phiên bản của make la 3.9. Để cài cmake >= 3.13, bạn phải cài build từ source.
$ wget https://github.com/Kitware/CMake/releases/download/v3.15.2/cmake-3.15.2.tar.gz
$ tar -zxvf cmake-3.15.2.tar.gz
$ cd cmake-3.15.2
$ ./bootstrap
$ make
$ sudo make installKiểm tra GCC:
$gcc --versionKết quả:
[fedora@ip-172-31-37-253 ~]$ gcc --version
gcc (GCC) 6.3.1 20161221 (Red Hat 6.3.1-1)Kiểm tra Python:
$ python3 --versionKết quả:
Python 3.5.1Kiểm tra SciPy:
$ python3 -c "import scipy;print(scipy.__version__)"
$ python3 -c "import numpy;print(numpy.__version__)"
$ python3 -c "import pandas;print(pandas.__version__)"
$ python3 -c "import sklearn;print(sklearn.__version__)"Kết quả:
0.16.1
1.11.0
0.18.0
0.17.1Kiểm tra Cmake
$ cmake --versionKết quả:
3.15.13.3. Cài đặt thư viện XGBoost
$ pip3 install xgboost==1.1Tại thời điểm viết bài, phiên bản mới nhất của xgboost là 1.2. Nhưng vì phiên bản của python=3.5 nên bạn chỉ có thể sử dụng được phiên bản 1.1 của xgboost.
Kiểm tra:
$ python3 -c "import xgboost;print(xgboost.__version__)"Kết quả:
1.1.04. Train XGBoost model
Tương tự như ở bài 9, chúng ta cũng sẽ sử dụng Otto dataset để kiểm tra khả năng của XGBoost model theo số lượng cores của CPU.
-
Tạo thư mục
xgboosttrên máy local, tạo filecheck_num_threads.pyvới code như sau:# Otto multi-core test from pandas import read_csv from xgboost import XGBClassifier from sklearn.preprocessing import LabelEncoder from time import time # load data data = read_csv('train.csv') dataset = data.values # split data into X and y X = dataset[:,0:94] y = dataset[:,94] # encode string class values as integers label_encoded_y = LabelEncoder().fit_transform(y) # evaluate the effect of the number of threads results = [] num_threads = [1, 16, 32] for n in num_threads: start = time() model = XGBClassifier(nthread=n) model.fit(X, label_encoded_y) elapsed = time() - start print(n, elapsed) results.append(elapsed)Copy file
train.csvở bài trước vào thư mụcxgboost. -
Tại cửa sổ Terminal của máy local, copy thư mục
xgboostlên EC2 Instance:$ scp -i xgboost-key.pem -r xgboost fedora@54.92.106.10:/home/fedora -
Tại của sổ Terminal kết nôi tới EC2 Instance, tiến hành chạy code:
$ cd xgboost python3 check_num_threads.pyKết quả thu được:
1 70.75178146362305 16 6.106862545013428 32 5.045598745346069Sử dụng 32 cores, mất 5s để train XGBoost model với tập dữ liệu tương đối lớn. Đây quả là một kết quả ấn tượng. 😀
Bonus:: Trong trường hợp việc train model mất nhiều thời gian hơn mà chẳng may bạn bị mất kết nối đến EC2 Instance giữa chừng thì thế nào? Bạn phải chạy train lại từ đầu ư? Quả là mất thời gian phải không? Giải pháp để ngăn chặn tình huống này, hoặc là bạn chạy lệnh train ở chế độ background process và ghi kết quả ra một file như lệnh sau:
$ nohup python script.py >script.py.out 2>&1 &hoặc bạn cũng có thể sử dụng Tmux.
5. Tắt EC2 EC2 Instance
Tiết kiệm là quốc sách hàng đầu, hãy luôn nhớ tắt EC2 EC2 Instance mỗi khi sử dụng xong. Bản thân mình đã từng một lần quên không tắt trong vài ngày. Kết quả là con số trên hóa đơn AWS tháng đó làm mình buồn mất cả tuần, :).
Để tắt EC2 EC2 Instance, đơn giản là làm theo như hình vẽ sau:

- Chọn 1->2->3 nếu bạn muốn tắt tạm thời (khi nào muốn dùng thì khởi động lên).
- Chọn 1->2->4 nếu bạn muốn xóa hẳn EC2 EC2 Instance này.
6. Kết luận
Trong bài viết này, chúng ta đã tìm hiểu cách cài đặt vào cấu hình EC2 Instance để train XGBoost model trên AWS.
Bài viết tiếp theo sẽ thiên về lý thuyết một chút, chúng ta sẽ tìm hiểu cách cấu hình hyper-parameters cho gradient boosting model. Hãy cùng đón đọc! 🙂
Toàn bộ source code của bài này các bạn có thể tham khảo trên github cá nhân của mình tại github.
Xem bài viết gốc tại đây.





Vui lòng đăng nhập để bình luận.