


Ta đã biết, XGBoost thực chất là tập hợp gồm nhiều decision tree. Việc thể hiện mỗi decision tree đó trên đồ thì sẽ giúp chúng ta hiểu sâu sắc hơn quá trình boosting khi đưa vào một tập dữ liệu. Trong bài này, hãy cùng tìm hiểu cách thức thể hiện đó từ một XGBoost model đã được train.
1. Vẽ một decision tree đơn lẻ
XGBoost Python API cung cấp một hàm cho việc vẽ các decision tree của một XGBoost model đã train, đó là plot_tree(). Hàm này nhận một tham số đầu tiên chính là model cần thể hiện.
plot_tree(model)Đồ thị vẽ ra bởi hàm này có thể được lưu dưới dạng file hoặc hiển thị trên màn hình bằng cách sử dụng hàm pyplot.show() của thư viện matplotlib. Yêu cầu là thư viện graphviz đã được cài đặt.
Để minh họa cho việc này, hãy cùng tạo một một XGBoost model và train nó trên tập dữ liệu Pima Indians onset of diabetes dataset. Code đầy đủ như bên dưới:
# plot decision tree
from numpy import loadtxt
from XGBoost import XGBClassifier
from XGBoost import plot_tree
from matplotlib import pyplot
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
y = dataset[:,8]
# fit model on training data
model = XGBClassifier()
model.fit(X, y)
# plot single tree
plot_tree(model)
pyplot.show()Đoạn code bên trên sẽ tạo ra một đồ thị của decision tree đầu tiên trong model (index 0). Các feature và feature value được thể hiện trên đồ thị.
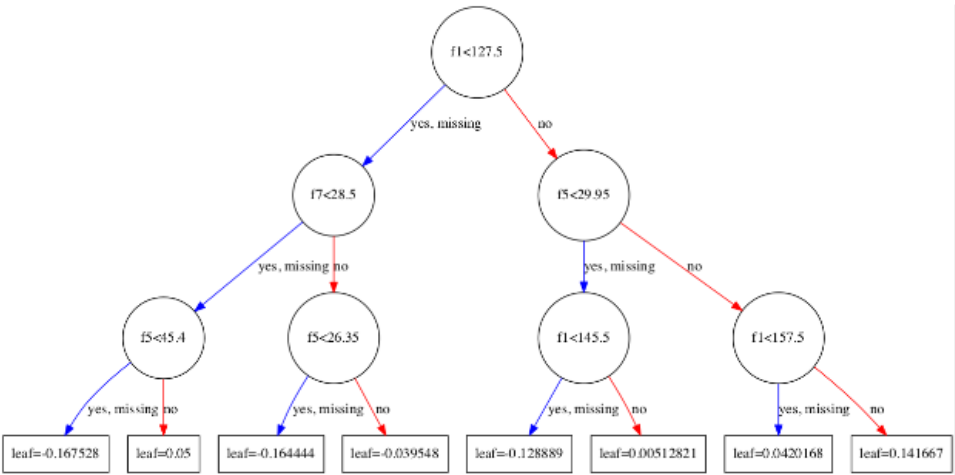
Một vài quan sát:
- Các
featuresđược đặt tên tự động từf1đếnf5tương ứng với cácfeature indicestrong dataset. - Trong mỗi node, hai hướng trái phải được phân biệt bằng màu sắc. Bên trái là màu xanh, trong khi bên phải là màu đỏ.
2. Một số tùy chọn
Ngoài tham số model cần vẽ là bắt buộc, hàm plot_tree() còn nhận vào một vài tham số tùy chọn khác:
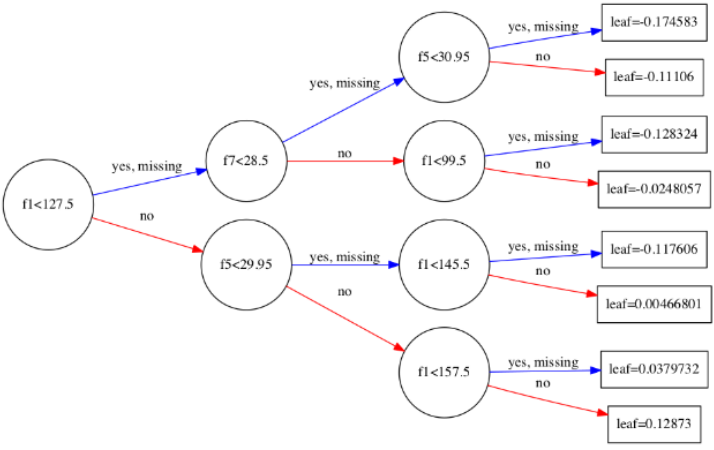
num_trees: Chỉ sốtreemuốn vẽ. Giá trị mặc định là 0. Ví dụ:plot_tree(model, num_trees=4)sẽ vẽ
boosted treethứ 5.rankdir: Hướng của đồ thị. Ví dụ: LR là left-to-right. Mặc định là UT – top-to-bottom.
Ví dụ:
plot_tree(model, num_trees=0, rankdir='LR')sẽ cho kết quả như sau:
3. Kết luận
Trong bài này, chúng ta đã tìm hiểu cách vẽ các decision tree của một XGBoost model đã train. Đây là cách rất hay giúp chúng ta có cái nhiều sâu hơn vào bên trong của model, hiểu rõ hơn cách thức mà model hoạt động.
Trong bài tiếp theo, chúng ta sẽ tìm hiểu cách lưu lại XGBoost model để train và sử dụng model đã lưu để dự đoán trên một mẫu data mới.
Toàn bộ source code của bài này các bạn có thể tham khảo trên github cá nhân của mình tại github.
Xem bài viết gốc tại đây.





Vui lòng đăng nhập để bình luận.